
순식간에 1월이 지나고 2월이 시작되었다.
벌써 한달이 지났다니 놀랍기만 하다.
아직도 모르는 것 투성이고, 언제나 에러메시지가 반겨주고있다.
그래도 꾸준히 하면 성과가 있지않을까 생각한다.
[6주차 정리]
1. Fundametals Node
◈ 파이썬 잘 하는 척 해보자
파이썬을 파이썬답게 활용하기 위해 알아야 할 핵심개념과 문법을 이해하고 실습해 본다.
- 정리
파이썬의 강점?
1) 생산성
파이썬의 강점은 생산성에 있다.
이 생산성은 똑같은 기능을 하는 프로그램을 얼마나 빨리 작성할 수 있는가에 달렸다.
2) 코드의 간결함
파이썬은 코드가 간결하다. 예시로 출력함수에 대해서 자바와 파이썬을 예시로 들 수 있다.
# java의 출력함수
if(true) {
System.out.println("첫 번째");
if(true) {
System.out.println("두 번째");
}
}
# 파이썬의 출력함수
if True :
print("첫 번째");
if True :
print("두 번째");3) 스크립트 언어
파이썬은 실시간으로 코드가 실행된다. 파이썬의 경우 인터프리터 방식을 사용하고있다.
한줄 한줄 코드가 작동되기 때문에 수정이 필요한 부분을 수정 후 바로바로 확인할 수 있다.
for문 잘써보기
1) enumerate()와 이중 for문
- enumerate() : 리스트, 문자열, 튜플 등이 있는 경우 순서와 리스트의 값을 함께 반환해주는 기능
my_list = ['a','b','c','d']
for i, value in enumerate(my_list):
print("순번 : ", i, " , 값 : ", value)
'''
출력
순번 : 0 , 값 : a
순번 : 1 , 값 : b
순번 : 2 , 값 : c
순번 : 3 , 값 : d
'''
- range([시작범위], 종료범위, [증가/감소 단위]) :
종료범위는 종료범위까지 진행되는 것이 아니라 종료범위 직전까지 진행됩니다.
- 리스트 컴프리헨션
for문을 길게 작성할 필요 없이 간결하게 표현한 방법
my_list = ['a','b','c','d']
result_list = []
for i in range(2):
for j in my_list:
result_list.append((i, j))
print(result_list)
##################################
my_list = ['a','b','c','d']
# 위의 이중for문을 간결하게 표현함.
result_list = [(i, j) for i in range(2) for j in my_list]
print(result_list)
◈ 다양한 데이터 전처리 기법
EDA를 통해 도출된 데이터 인사이트를 토대로,
효과적인 Feature Engineering을 위해 사용하는 Encoding, Scaling,
Feature Selection 등의 전처리 기법을 실습해 본다.
- 정리
1) 결측치 확인
- 전체 데이터 건수 확인 : len()활용
- 무의미한 데이터 칼럼 삭제 : data.drop('삭제할칼럼',axis=1)활용
- 결측데이터 개수 확인 : len()-data.count()활용
- 결측데이터 확인 : data[data.isnull().any(axis=1)] 활용
- data.dropna()
data.dropna(how='all', subset=['수출건수', '수출금액', '수입건수', '수입금액', '무역수지'], inplace=True)
# data.dropna() : 결측치를 삭제해주는 메서드
# subset=[] : 결측치를 확인할 칼럼들
# how : 해당 부분이 전부 결측치인경우 삭제
# any : 하나라도 결측치인 경우 삭제
# inplace : 데이터프레임 내부에 바로 적용
2) 중복된 데이터
- data.duplicated() : 중족된 데이터 존재유무 확인
- data[data.duplicated()] : 중족된 데이터 출력
- data[(data['기간']=='2020년 03월')&(data'국가명']=='중국')]
data에서 '기간'칼럼에서 2020년 03월 인 행과 '국가명'칼럼에서 '중국'인 행렬 출력
- data.drop_duplicates(inplace=True) : 중복 데이터 제거
3) 이상치 찾는방법
- z-score method
'''
abs(df[col] - np.mean(df[col]))
=> 데이터에서 평균을 빼준 것에 절대값을 취합니다.
abs(df[col] - np.mean(df[col]))/np.std(df[col])
=> 위에 한 작업에 표준편차로 나눠줍니다.
df[abs(df[col] - np.mean(df[col]))/np.std(df[col])>z].index
=> 값이 z보다 큰 데이터의 인덱스를 추출합니다.
'''
def outlier(df, col, z):
return df[abs(df[col] - np.mean(df[col]))/np.std(df[col])>z].index
- IQR method

위 그림의 Q1 - 1.5 x IQR 과 Q1 + 1.5 x IQR의 범위 바깥을 이상치라고 규정합니다.
def outlier2(df, col):
q1 = df[col].quantile(0.25)
q3 = df[col].quantile(0.75)
iqr = q3 - q1
return df[(df[col] < q1-1.5*iqr)|(df[col] > q3+1.5*iqr)]
◈ 선형 회귀와 로지스틱 회귀
선형 회귀와 로지스틱 회귀의 개념을 익히고 유방암 데이터 셋으로 실습해본다.
- 정리
회귀분석이란?
관찰된 여러 데이터를 기반으로 각 연속형 변수간의 관계를 모델링하고
이에대한 적합도를 측정하는 분석 방법입니다.
개인적으로는 여러 데이터들간의 상관관계를 찾아
오차를 최소화하는 함수를 만들어내는 것이라고 생각합니다.
분류와 회귀?
분류
데이터 x의 여러 feature 값들을 이용하여 해당 데이터의 클래스 y를 추론하는 것.
회귀
데이터 x의 여러 feature 값들을 이용하여 연관된 다른 데이터 y의 정확한 값을 추론하는 것.
선형회귀?
종속변수 Y와 한 개 이상의 독립변수 X와의 선형 상관관계를 모델링하는 회귀분석 기법입니다.
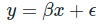
식으로는 위와같이 나타낼 수 있으며, ε은 종속변수와 독립변수 사이의 오차를 의미합니다.
선형회귀는 잔차의 제곱의 합을 최소로 하는 가중치와 편향값을 구하는 분석방법입니다..
여기서 잔차는 추정값과 실제 데이터의 차이를 의미합니다.
로지스틱 회귀분석?
데이터가 어떤 범주에 속할 확률을 0에서 1 사이의 값으로 예측하고
그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 지도 학습 알고리즘입니다.

2. Exploration Node
◈ 나의 첫번째 캐글 경진대회, 무작정 따라해보기
인생에서 처음 시도해보는 캐글 경진대회였다.
비록 예전에 진행했던 것을 예시로 진행하며,
어떤식으로 진행해야하는지 가이드라인을 잡아준 것 뿐이었지만
이전에 겪어보지 않아서 모든것이 새롭고 흥미로웠다.
이전노드들에서 배웠던 데이터의 처리방식등을 활용할 수 있었던 노드였다.
물론 활용하면서 판다스나 넘파이 등에 좀 더 익숙해져야겠다는 느낌을 받았다.
머리로는 이렇게하면 될것 같은데 하는데 정작 코드는 기억이 하나도 안나서
열심히 구글링하고 지난 노드들을 다시 살펴보고 했다.
그래도 그런 과정들이 재밌었던 노드였다.
Face Embedding project github (차후 링크예정)
◈ 인물사진을 만들어보자
해당노드는 단순한 인물사진을 가지고
포토샵에서 배경만 블러처리했던 것같은 효과를 만드는 노드였다.
아직 본격적으로 시작해야지 하는 느낌은 아니라서
최대한 이해할수있는 부분만 이해하고 넘긴부분이 많다.
프로젝트를 진행하면서 좀더 꼼꼼하게 복습하고 진행해야겠다.
영화 추천시스템 project github (차후 링크예정)
3. 알고리즘
◈ 5주차
이번주에 풀이했던 부분은 9장 스택.
스택은 그래도 이전에 연결리스트를 하면서
관련된 부분을 공부했던 기억이 있어 그래도 할만하긴 했다.
단지 할만한 부분이 답지를 보고 이해하는것이었을 뿐...
문제를 푸는건 여전히 똑같이 어려웠다.
개념방향을 어떻게 잡아야할지부터 살짝 버거운 일이었다.
이번에 코딩마스터 중급반이 열렸다는데
솔직히 혹하긴했다.
그래도 어려운곳에서 고통받고나면
시간이 지났을때 좀더 나을것이라고 판단한다.
4. DeepML(CS231n)
◈ 5주차 (Lecture 6 : Backpropagation) :
이번주 lecture는 생각보다 이해하는게 어렵지 않았다. 이게 다 밑시딥 스터디 덕분인것 같다.
공부하기 싫어도, 책을 못읽어도, 이해를 잘 못했어도 멱잘잡고 캐리당하는 기분이었다.
스터디가 끝나면 그래도 어느정도 잔상처럼 남는 부분들이 있어서
그러한 부분들이 쌓여서 동영상강의를 볼때 이해를 돕게된다.
밑시딥을 하길 잘했다는 생각이 드는 부분이었다.
'[SSAC X AIFFEL]' 카테고리의 다른 글
| [9주차]SSAC X AIFFEL (02.22~02.26) (0) | 2021.02.26 |
|---|---|
| [8주차]SSAC X AIFFEL (02.15~02.19) (0) | 2021.02.19 |
| [5주차]SSAC X AIFFEL (01.25~01.29) (0) | 2021.01.29 |
| [4주차]SSAC X AIFFEL (01.18~01.22) (0) | 2021.01.22 |
| [3주차]SSAC X AIFFEL (01.11~01.15) (1) | 2021.01.15 |