
2.3 Predicting Ratings with Neighborhood-Based Methods(2)
2.3.1.1 Similarity Function Variants
- 추천시스템에서 유사도를 구하는 함수들은 다양한 변형이 존재합니다.
- 이번 파트에서는 이 변형된 함수들을 살펴보려고 합니다.
첫 번째 변형
- 평균 중심 등급이 아닌 원시 등급(user가 매긴 등급)에 코사인 함수를 사용하는 것입니다.
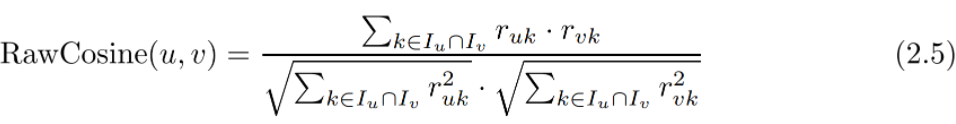
- 일부 구현에서는 원시 코사인 함수의 분모 부분에서 정규화 요인이 상호 평가 항목이 아닌 지정된 항목 전체로 변경하는 경우도 있습니다.

- 실제로는 분모 범위의 차이 뿐이지만 어떤 항목을 기준으로 하는가가 큰 차이라고 생각합니다.
- 일반적으로 평균 중심 등급의 편향 조정 효과 때문에 원시 코사인보다 피어슨 상관계수가 더 좋습니다.
- 이는 '코사인 유사도'가 크기는 동일한 상태에서 방향의 차이만 고려하고, 이에 반해 '피어슨 상관계수'는 크기와 방향의 차이까지 고려하기 때문에 발생하는 차이입니다.
두 번째 변형
- target으로 하는 user와 참조하는 user간의 공통 등급이 적은 경우에는 예측 등급이 생각하지 못한 값으로 도출 될 수 있습니다.
- 이를 방지하기 위해서 공통 등급의 개수에 따라 가중치를 부여하게 됩니다.
- 즉 해당 사용자 쌍의 중요성을 강조하기 위해서 할인 계수를 사용하는 것입니다.
- 이를 유의 가중치라고 합니다.
- 할인 계수를 사용하는 것은 두 사용자 사이의 공통 등급 수가 특정 임계값(β)보다 작을 때 시작됩니다.
- 할인 계수가 적용된 유사성 함수를 DiscountedSim()라고 하며 아래와 같이 계산됩니다.

2.3.1.2 Variants of the Prediction Function
- 이번 파트에서는 예측 함수의 변형에 관해서 알아보겠습니다.
첫 번째 변형
- 평균 중심 등급 대신 평균 중심 등급에 사용자 u가 매긴 등급들의 표준편차로 평균 중심 등급을 나눕니다.
- 표준 편차는 아래와 같이 정의됩니다.

- 그 후 아래와 같이 표준화 된 등급을 계산합니다.

- 이제 기존의 예측 등급을 구하는 식에서 이를 대입하여 값을 계산합니다.
- 계산식은 아래와 같습니다.

- 기존 식은 아래와 같습니다.
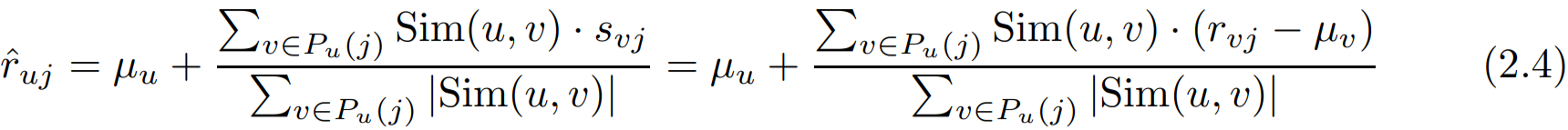
- 변경된 부분들을 살펴보겠습니다. 기존 평균 중심 등급인 s_vj가 z_vj로 바뀌면서 기준이 z-score로 바뀌었습니다.
- 또한 표준편차를 곱해주는 부분이 새로 생겼는데 이는 등급 정규화 중에 활용된 표준편차를 최종적으로 곱해주는 부분입니다.
- 이렇게 z-score를 활용한 변형 방법의 경우는 예측 등급이 허용 등급 범위를 자주 벗어날 수 있다는 문제가 발생할 수 있습니다.
두 번째 변형
- 첫 번째 변형에서 s_vj 부분을 z-score를 활용하여 변경하였습니다.
- 두 번째 변형은 가중치의 역할을 하는 유사도 함수를 변형하는 방법입니다.
- 기존에 활용한 유사도 함수는 피어슨 상관계수를 가중치로 활용하는 방법이었습니다.
- 이를 거듭제곱으로 곱하여 증폭하는 방법 도 있습니다.

- 위와 같이 제곱 수를 1보다 큰 수를 선택함으로써 가중치에서의 유사성의 중요성 자체를 증폭 시킬 수 있습니다.
- 그러나 위와 같은 방법을 사용하게 된다면 평가 등급의 세분화가 많이 되어있는 경우에 등급 간에 많은 순서 정보를 잃게 될 수 있습니다.
- 개인적인 판단으로는 기존의 피어슨 상관계수의 경우 음수값이 포함되어 있어서 이를 토대로 음수에서 양수로 가는 순서 정보가 존재했는데, 이를 제곱 할 경우 이 순서 정보가 파괴되기 때문이라고 생각합니다.
2.3.1.3 Variations in Filtering Peer Groups
- 이번 파트는 타겟으로 삼은 user의 피어 그룹을 다양한 방법으로 정의하고 필터링 하는 파트입니다.
상위 k명
- 가장 간단한 방법은 타겟으로 삼은 user와 가장 유사한 상위 k명을 피어그룹으로 사용하는 것입니다.
- 그러나 이러한 방법의 경우에는 유사도 함수에 따라 대상과 관계성이 약하거나 음의 상관관계가 있는 사용자가 포함 될 수 있습니다.
- 이러한 사용자는 예측에서 오류를 야기할 수 있습니다.
- 또한 관계성이 약하거나 음의 상관관계의 사용자를 포함하는 것은 이웃기반 방식의 광범위한 원칙과 일치하지 않습니다.
- 따라서 위의 방법에서 관계성이 약하거나 음의 상관관계의 평가 등급은 종종 걸러집니다.
2.3.1.4 Impact of the Long Tail
- 일반적으로 실제 시나리오에서는 평가 등급 분포는 긴 꼬리 분포를 보여주는 경우가 많습니다.
- 이러한 긴꼬리 분포는 항목을 추천하는 부분에서 자주 평가된 항목들을 지속적으로 추천해주어 서로 다른 user간의 차별성이 떨어지는 경향이 있습니다.
- 해당 문제점을 보완하기 위해서 문서 정보 검색 등에서 사용되는 개념인 역 문서 빈도와 유사한 역 사용자 빈도 개념을 활용합니다.
- m_j가 item인 j의 등급 수이고 m이 총 user의 수라면 항목 j의 가중치 w_j는 다음과 같이 설정됩니다.

- 위에서 계산한 w_j는 아래와 같이 가중치를 포함하도록 피어슨 상관 계수를 수정 할 수 있습니다.

- 위의 w_j와 같은 item 가중치는 다른 협업 필터링 방법에도 포함될 수 있습니다.
'[Rec-Sys]' 카테고리의 다른 글
| [ch02] 2.3 Predicting Ratings with Neighborhood-Based Methods(4) (0) | 2021.12.27 |
|---|---|
| [ch02] 2.3 Predicting Ratings with Neighborhood-Based Methods(3) (0) | 2021.12.22 |
| [ch02] 2.3 Predicting Ratings with Neighborhood-Based Methods(1) (0) | 2021.12.08 |
| [Ch02] 2.2 Key Properties of Ratings Matrices (0) | 2021.12.02 |
| [Ch02] 2.1 Introduction (0) | 2021.12.01 |