
0. 들어가며
학습목표
→ Extractive/Abstractive summarization 이해하기
→ 단어장 크기를 줄이는 다양한 text normalization 적용해보기
→ seq2seq의 성능을 Up시키는 Attention Mechanism 적용하기
→ Kaggle에서 제공된 아마존 리뷰 데이터셋을 활용하여 요약해보기
1. 텍스트 요약이란?

→ 텍스트 요약(Text Summarization)은 긴 길이의 문서 원문을 핵심 주제만으로 구성된 짧은 문장들로 변환하는 것을 말한다.
추출적 요약(Extractive Summarization)
→ 전통적인 머신 러닝 방식에 속하는 텍스트 랭크(TextRank)와 같은 알고리즘을 사용하는 방법
→ 여러개의 문장으로 구성 된 텍스트가 있다면, 그 중 핵심적인 문장 몇 개를 꺼내와서 그 문장으로 구성된 요약문을 만드는 형식
→ 결과로 나온 문장들 간의 호응이 자연스럽지 않아 연결이 어색할 수 있다.
→ ex) 네이버 뉴스 서비스의 요약봇

추상적 요약(Abstractive Summarization)
→ 원문으로부터 내용이 요약된 새로운 문장을 생성하는 것을 말한다.
→ 자연어 처리 분야 중 자연어 생성(Natural Language Generation; NLG)
→ 원문을 구성하는 문장 중 어느 것이 요약문에 들어갈 핵심문장인지를 판별한다는 점에서 문장 분류라고도 할 수 있다.

2. Attention
RNN(Recurrent Neural Network)


→ 맥락의 흐름을 기억할 수 있는 모델
→ 문장이 길어질 경우 기울기 소실 혹은 기울기 폭발이 일어난다
LSTM(Long Short-Term Memory models)

→ RNN셀의 기울기 폭발, 소실문제를 해결하고 학습 또한 빠르게 수렴한다.
각 gate 설명
- forget gate
- 입력받은 값(이전 결과+새로운 값)의 중요도를 판별한다
- generate
- 입력받은 값(이전 결과+새로운 값)의 새로운 정보를 기억셀에 추가한다
- input gate
- 입력받은 값(이전 결과+새로운 값)을 얼마나 추가할지 조절한다
- output gate
- 얼마나 적용할지는 이전결과+새로운 값으로 판단한다
- 새로 만들어진 기억셀의 값을 다음 은닉상태에 얼마나 적용할지 판단
Seq2Seq(Sequence to Sequence)

→ 기존 LSTM에서 발전된 형태로 주로 번역문제를 다룰 때 사용되었다.
→ 기존 LSTM이 RNN의 기울기 소실 문제를 해결했다면, Seq2Seq는 번역에 따른 어순변경 문제를 해결하였다.
→ LSTM을 하나로만 연결한 것이 아니라 문장이 입력되는 Encoder에서 입력문장을 대표하는 Context Vector를 만들어 문장을 출력하는 Decoder에 전달해 문장을 만들도록 하였다.
→ 이는 문장 전체를 보고 나서 문장을 생성하게끔 만드는 구조이다.
Attention
→ Seq2Seq 모델은 문장 전체를 하나의 Context Vector로 대표하여 Decoder에 전달해 주었다.
→ 이는 긴 문장이 입력될 경우 데이터의 커다란 손실을 야기하여 문장을 제대로 출력하지 못한다.
→ 이를 해결하기위해 문장을 출력할 때마다 해당 문장에 가장 큰 영향을 끼치는 원문장을 찾아 참고하는 매커니즘이다.
→ Decoder의 현재 Step이 어디냐에 따라 Incoder의 각 Step에서의 Hidden state의 정보를 얼마나 반영할 지를 Attention Weights로 정한다.
→ 따라서 Decoder의 현재 Step에 따라서 Attention Weights의 값들이 계속 달라진다.
→ Attention의 방식은 기초적인 Bahdanau Attention과 약간 발전시킨 Luong Attention 방식이 있다.
→ 둘의 차이는 Decoder의 현재 Hidden state를 구하기 위해 이전 Hidden state를 활용 하느냐 여부에 따른다.
3. 데이터 준비부터 모델의 완성까지
데이터 준비
→ 데이터 셋은 Kaggle에서 제공된 아마존 리뷰 데이터셋이다.
링크 : https://www.kaggle.com/snap/amazon-fine-food-reviews
→ 링크에서 다운받아도 되고 아래의 링크를 클릭해 직접 받아도 된다.
→ 위 아마존 리뷰 데이터셋은 영문 데이터로 영문을 처리하는데 편리한 NLTK(Natural Language Toolkit)을 사용한다.
→ BeautifulSoup4는 크롤링에도 사용되는 라이브러리이며 문서를 파싱하는데 사용하는 패키지 이다.
$ pip install nltk
$ pip install beautifulsoup4
→ 이제 NLTK패키지에서 불용어 처리를 위한 사전을 다운받고 데이터 전처리에 필요한 나머지 패키지를 받은 후 데이터를 확인해보겠다.
import nltk
nltk.download('stopwords')
import numpy as np
import pandas as pd
import os
import re
import matplotlib.pyplot as plt
from nltk.corpus import stopwords
from bs4 import BeautifulSoup
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import urllib.request
→ 전체 데이터는 크기가 너무 크기 때문에 데이터의 크기를 10만개로 제한하여 확인한다.
data = pd.read_csv(os.getenv("HOME")+"/work/news_summarization/data/Reviews.csv", nrows = 100000)
print('전체 샘플수 :',(len(data)))
# 출력결과
100000
data.head()

→ 모델의 학습에 필요한 부분은 Summary와 Text부분이므로 해당열만 남기고 삭제한다.
data = data[['Text','Summary']]
data.head()
#랜덤한 15개 샘플 출력
data.sample(15)

데이터 전처리
중복제거
→ 먼저 데이터의 중복을 배제하기위하여 유일한 샘플의 수를 확인해본다.
print('Text 열에서 중복을 배제한 유일한 샘플의 수 :', data['Text'].nunique())
print('Summary 열에서 중복을 배제한 유일한 샘플의 수 :', data['Summary'].nunique())
# 출력결과
Text 열에서 중복을 배제한 유일한 샘플의 수 : 88426
Summary 열에서 중복을 배제한 유일한 샘플의 수 : 44187
→ Summary의 경우 원문의 요약이므로 대표단어 혹은 문장이 같다면 중복될 가능성이 높다.
→ 따라서 중복을 배제하는 열은 Text열로 한다.
data.drop_duplicates(subset = ['Text'], inplace = True)
print('전체 샘플수 :',(len(data)))
# 출력결과
전체 샘플수 : 88426
Null값 제거
→ 중복값을 제거해주는 와중에 Null값이 생기거나, 애초에 Null값이 존재하는 경우도 있으니 이를 확인하여 배제한다.
data.dropna(axis = 0, inplace = True) # axis를 0으로 하면 Null값이 존재하는 행을 삭제한다.
print('전체 샘플수 :',(len(data)))
# 출력결과
전체 샘플수 : 88425
텍스트 정규화와 불용어
→ 영문의 경우 I am을 I'm의 형식으로 표현하는 경우가 많아 모델이 학습할 경우 같은 말임에도 불구하고 두개의 단어로 인식하는 경우가 있다.
→ 이를 해결하기 위해 텍스트 정규화 과정을 거친다.
→ 정규화 과정을 진행하기 위해 정규화 시킬 단어사전을 만든다.
contractions = {"ain't": "is not", "aren't": "are not","can't": "cannot", "'cause": "because", "could've": "could have", "couldn't": "could not",
"didn't": "did not", "doesn't": "does not", "don't": "do not", "hadn't": "had not", "hasn't": "has not", "haven't": "have not",
"he'd": "he would","he'll": "he will", "he's": "he is", "how'd": "how did", "how'd'y": "how do you", "how'll": "how will", "how's": "how is",
"I'd": "I would", "I'd've": "I would have", "I'll": "I will", "I'll've": "I will have","I'm": "I am", "I've": "I have", "i'd": "i would",
"i'd've": "i would have", "i'll": "i will", "i'll've": "i will have","i'm": "i am", "i've": "i have", "isn't": "is not", "it'd": "it would",
"it'd've": "it would have", "it'll": "it will", "it'll've": "it will have","it's": "it is", "let's": "let us", "ma'am": "madam",
"mayn't": "may not", "might've": "might have","mightn't": "might not","mightn't've": "might not have", "must've": "must have",
"mustn't": "must not", "mustn't've": "must not have", "needn't": "need not", "needn't've": "need not have","o'clock": "of the clock",
"oughtn't": "ought not", "oughtn't've": "ought not have", "shan't": "shall not", "sha'n't": "shall not", "shan't've": "shall not have",
"she'd": "she would", "she'd've": "she would have", "she'll": "she will", "she'll've": "she will have", "she's": "she is",
"should've": "should have", "shouldn't": "should not", "shouldn't've": "should not have", "so've": "so have","so's": "so as",
"this's": "this is","that'd": "that would", "that'd've": "that would have", "that's": "that is", "there'd": "there would",
"there'd've": "there would have", "there's": "there is", "here's": "here is","they'd": "they would", "they'd've": "they would have",
"they'll": "they will", "they'll've": "they will have", "they're": "they are", "they've": "they have", "to've": "to have",
"wasn't": "was not", "we'd": "we would", "we'd've": "we would have", "we'll": "we will", "we'll've": "we will have", "we're": "we are",
"we've": "we have", "weren't": "were not", "what'll": "what will", "what'll've": "what will have", "what're": "what are",
"what's": "what is", "what've": "what have", "when's": "when is", "when've": "when have", "where'd": "where did", "where's": "where is",
"where've": "where have", "who'll": "who will", "who'll've": "who will have", "who's": "who is", "who've": "who have",
"why's": "why is", "why've": "why have", "will've": "will have", "won't": "will not", "won't've": "will not have",
"would've": "would have", "wouldn't": "would not", "wouldn't've": "would not have", "y'all": "you all",
"y'all'd": "you all would","y'all'd've": "you all would have","y'all're": "you all are","y'all've": "you all have",
"you'd": "you would", "you'd've": "you would have", "you'll": "you will", "you'll've": "you will have",
"you're": "you are", "you've": "you have"}
print("정규화 사전의 수: ",len(contractions))
# 출력결과
정규화 사전의 수: 120
→ 텍스트 정규화 이외에도 단순 자연어 처리에 도움이 되지않는 단어(불용어)를 처리하기 위해 NLTK에서 제공하는 불용어 리스트를 참조하여 불용어를 제거한다.
print('불용어 개수 :', len(stopwords.words('english') ))
print(stopwords.words('english'))
# 출력결과
불용어 개수 : 179
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]`
→ 추가적인 처리가 필요했던 정규화, 불용화 과정의 준비가 끝났으니 부차적인 소문자화, html태그제거, 특수문자 제거 등의 일련의 과정을 함수로 만들어 전처리를 진행한다.
→ Text의 경우 불용어를 제거해야하고 Summary의 경우 Text를 이용해 생성하는 것이므로 불용어를 따로 제거하지 않는다.
#데이터 전처리 함수
def preprocess_sentence(sentence, remove_stopwords=True):
sentence = sentence.lower() # 텍스트 소문자화
sentence = BeautifulSoup(sentence, "lxml").text # <br />, <a href = ...> 등의 html 태그 제거
sentence = re.sub(r'\\([^)]*\\)', '', sentence) # 괄호로 닫힌 문자열 (...) 제거 Ex) my husband (and myself!) for => my husband for
sentence = re.sub('"','', sentence) # 쌍따옴표 " 제거
sentence = ' '.join([contractions[t] if t in contractions else t for t in sentence.split(" ")]) # 약어 정규화
sentence = re.sub(r"'s\\b","",sentence) # 소유격 제거. Ex) roland's -> roland
sentence = re.sub("[^a-zA-Z]", " ", sentence) # 영어 외 문자(숫자, 특수문자 등) 공백으로 변환
sentence = re.sub('[m]{2,}', 'mm', sentence) # m이 3개 이상이면 2개로 변경. Ex) ummmmmmm yeah -> umm yeah
# 불용어 제거 (Text)
if remove_stopwords:
tokens = ' '.join(word for word in sentence.split() if not word in stopwords.words('english') if len(word) > 1)
# 불용어 미제거 (Summary)
else:
tokens = ' '.join(word for word in sentence.split() if len(word) > 1)
return tokens
temp_text = 'Everything I bought was great, infact I ordered twice and the third ordered was<br />for my mother and father.'
temp_summary = 'Great way to start (or finish) the day!!!'
print(preprocess_sentence(temp_text))
print(preprocess_sentence(temp_summary, False)) # 불용어를 제거하지 않습니다.
# 출력결과
everything bought great infact ordered twice third ordered wasfor mother father
great way to start the day
→ 함수를 활용하여 데이터셋의 전처리를 진행한
clean_text = []
# 전체 Text 데이터에 대한 전처리 : 10분 이상 시간이 걸릴 수 있습니다.
for s in data['Text']:
clean_text.append(preprocess_sentence(s))
clean_summary = []
# 전체 Summary 데이터에 대한 전처리 : 5분 이상 시간이 걸릴 수 있습니다.
for s in data['Summary']:
clean_summary.append(preprocess_sentence(s, False))
data['Text'] = clean_text
data['Summary'] = clean_summary
# 빈 값을 Null 값으로 변환
data.replace('', np.nan, inplace=True)
→ 빈 값을 Null로 처리하는 이유는 전처리를 통해 문장이 제거되었을 때 전체 문장이 제거되어 값이 없는 경우를 배제해주기 위해서이다.
→ Null로 처리된 값들을 배제해준다.
data.dropna(axis=0, inplace=True)
데이터 나누기
→ 문장 데이터의 경우 학습에 사용할 데이터의 크기를 정하는 것이 중요하다.
→ 문장 데이터의 크기가 클경우 데이터를 포괄적으로 포함하지만 학습이 잘 안될 수 있다.(개인적인 생각)
최대 길이 정하기
→ 최대 길이를 정해주기 위해 데이터셋의 각 열의 최소, 최대, 평균 길이를 확인한다.
# 길이 분포 출력
import matplotlib.pyplot as plt
text_len = [len(s.split()) for s in data['Text']]
summary_len = [len(s.split()) for s in data['Summary']]
print('텍스트의 최소 길이 : {}'.format(np.min(text_len)))
print('텍스트의 최대 길이 : {}'.format(np.max(text_len)))
print('텍스트의 평균 길이 : {}'.format(np.mean(text_len)))
print('요약의 최소 길이 : {}'.format(np.min(summary_len)))
print('요약의 최대 길이 : {}'.format(np.max(summary_len)))
print('요약의 평균 길이 : {}'.format(np.mean(summary_len)))
plt.subplot(1,2,1)
plt.boxplot(summary_len)
plt.title('Summary')
plt.subplot(1,2,2)
plt.boxplot(text_len)
plt.title('Text')
plt.tight_layout()
plt.show()
plt.title('Summary')
plt.hist(summary_len, bins = 40)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()
plt.title('Text')
plt.hist(text_len, bins = 40)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()
# 출력결과
텍스트의 최소 길이 : 2
텍스트의 최대 길이 : 1235
텍스트의 평균 길이 : 38.792428272310566
요약의 최소 길이 : 1
요약의 최대 길이 : 28
요약의 평균 길이 : 4.010729443721352
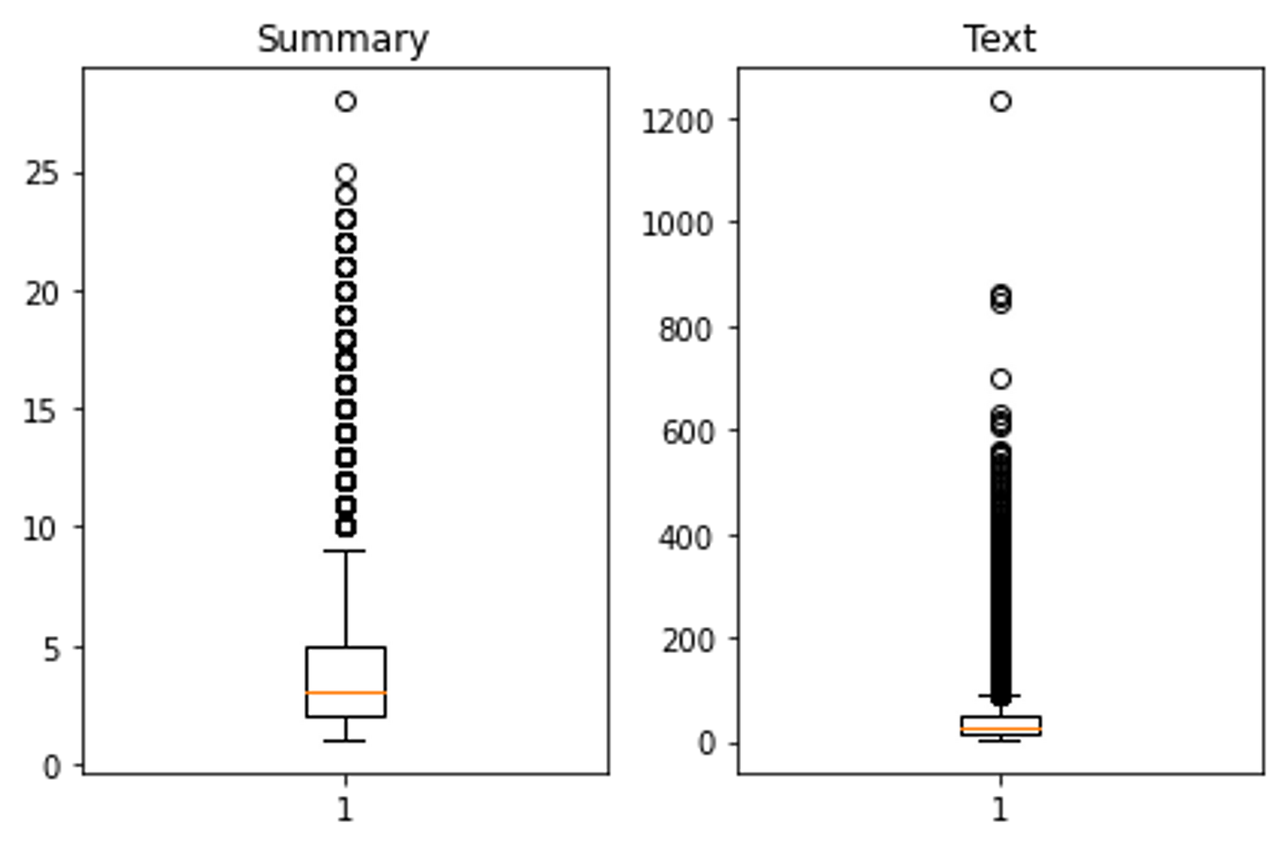
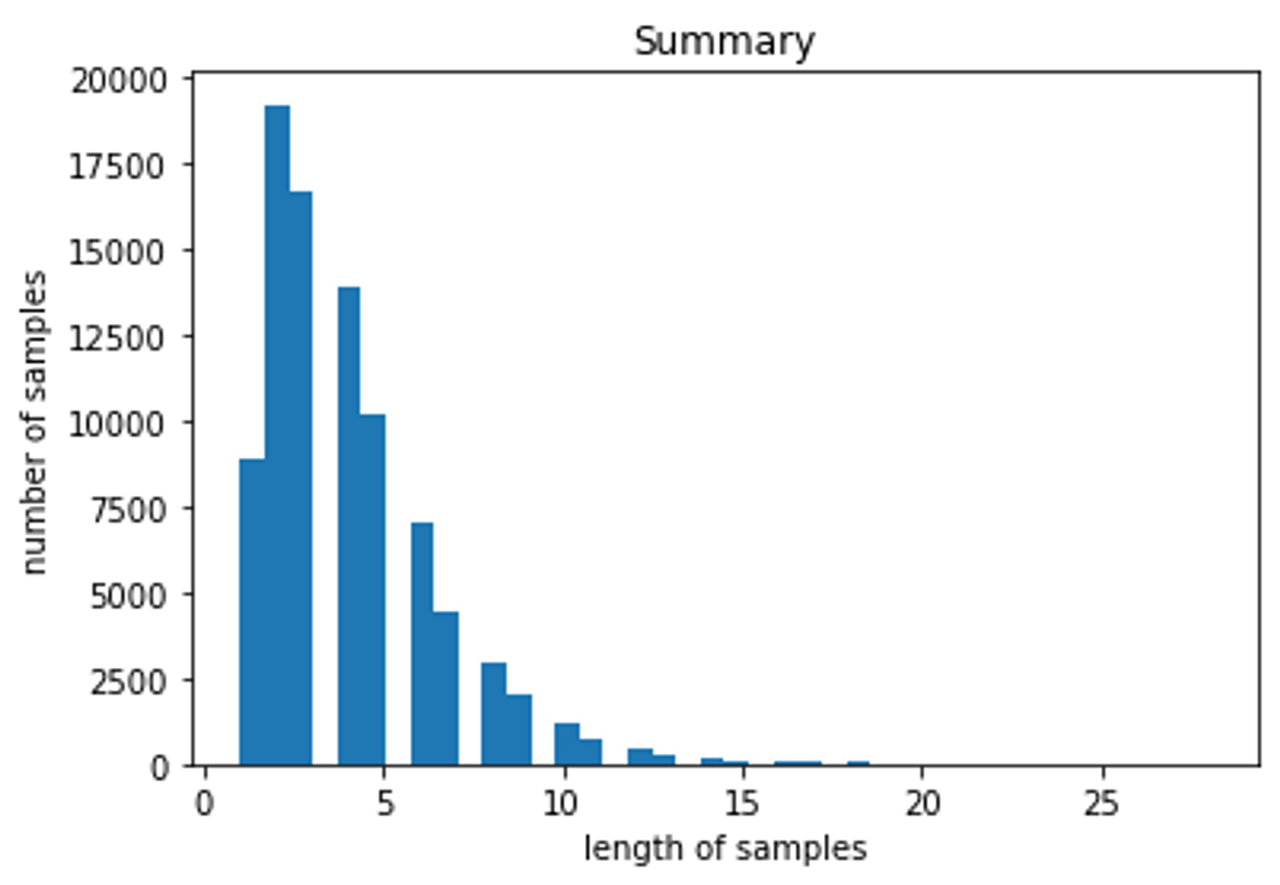

→ 각 데이터를 적당한 크기를 기준으로 제외한다.
data = data[data['Text'].apply(lambda x: len(x.split()) <= text_max_len)]
data = data[data['Summary'].apply(lambda x: len(x.split()) <= summary_max_len)]
print('전체 샘플수 :',(len(data)))
# 출력결과
전체 샘플수 : 65818
Encoder & Decoder 값으로 바꿔주기
→ Encoder의 경우는 문장이 그대로 들어가지만 Decoder의 경우 입력값엔 문장의 앞에 시작토큰이 출력값엔 문장의 끝에 종료 토큰이 붙는다.
#요약 데이터에는 시작 토큰과 종료 토큰을 추가한다.
data['decoder_input'] = data['Summary'].apply(lambda x : 'sostoken '+ x)
data['decoder_target'] = data['Summary'].apply(lambda x : x + ' eostoken')
data.head()

→ 데이터프레임형식으로 되어있는 데이터셋을 학습을 위해 Numpy타입으로 저장해준다.
encoder_input = np.array(data['Text']) # 인코더의 입력
decoder_input = np.array(data['decoder_input']) # 디코더의 입력
decoder_target = np.array(data['decoder_target']) # 디코더의 레이블
데이터셋 분리
→ 이전에는 train test split 패키지를 사용해서 데이터셋을 분리했지만 이번 노드에서는 수동으로 분리하였다.
→ 분리해주기 이전에 데이터셋을 섞기위해 np.random.shuffle을 사용했다.
indices = np.arange(encoder_input.shape[0])
np.random.shuffle(indices)
print(indices)
# 출력결과
[ 908 19371 60325 ... 23200 53481 15848]
encoder_input = encoder_input[indices]
decoder_input = decoder_input[indices]
decoder_target = decoder_target[indices]
→ 이제 데이터셋을 분리해주기위해 인덱스를 설정한다.
n_of_val = int(len(encoder_input)*0.2)
print('테스트 데이터의 수 :',n_of_val)
# 출력결과
테스트 데이터의 수 : 13163
encoder_input_train = encoder_input[:-n_of_val]
decoder_input_train = decoder_input[:-n_of_val]
decoder_target_train = decoder_target[:-n_of_val]
encoder_input_test = encoder_input[-n_of_val:]
decoder_input_test = decoder_input[-n_of_val:]
decoder_target_test = decoder_target[-n_of_val:]
print('훈련 데이터의 개수 :', len(encoder_input_train))
print('훈련 레이블의 개수 :',len(decoder_input_train))
print('테스트 데이터의 개수 :',len(encoder_input_test))
print('테스트 레이블의 개수 :',len(decoder_input_test))
# 출력결과
훈련 데이터의 개수 : 52655
훈련 레이블의 개수 : 52655
테스트 데이터의 개수 : 13163
테스트 레이블의 개수 : 13163
정수인코딩 & 패딩
정수인코딩
→ 컴퓨터는 문장 그대로를 처리할 수 없기 때문에 훈련 데이터와 테스트 데이터를 모두 정수로 바꾸어야 한다.
→ 해당 노드에서는 Keras의 토크나이저를 사용하여 입력된 훈련데이터로부터 단어 사전을 만든다.
src_tokenizer = Tokenizer() # 토크나이저 정의
src_tokenizer.fit_on_texts(encoder_input_train) # 입력된 데이터로부터 단어 집합 생성
→ 학습을 좀 더 원활하게 하기위하여 문장에서 등장하는 빈도수를 확인하여 이를 기준으로 학습데이터에서 배제한다.
threshold = 7
total_cnt = len(src_tokenizer.word_index) # 단어의 수
rare_cnt = 0 # 등장 빈도수가 threshold보다 작은 단어의 개수를 카운트
total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합
rare_freq = 0 # 등장 빈도수가 threshold보다 작은 단어의 등장 빈도수의 총 합
# 단어와 빈도수의 쌍(pair)을 key와 value로 받는다.
for key, value in src_tokenizer.word_counts.items():
total_freq = total_freq + value
# 단어의 등장 빈도수가 threshold보다 작으면
if(value < threshold):
rare_cnt = rare_cnt + 1
rare_freq = rare_freq + value
print('단어 집합(vocabulary)의 크기 :',total_cnt)
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print('단어 집합에서 희귀 단어를 제외시킬 경우의 단어 집합의 크기 %s'%(total_cnt - rare_cnt))
print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100)
print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100)
# 출력결과
단어 집합(vocabulary)의 크기 : 32019
등장 빈도가 6번 이하인 희귀 단어의 수: 23774
단어 집합에서 희귀 단어를 제외시킬 경우의 단어 집합의 크기 8245
단어 집합에서 희귀 단어의 비율: 74.24966426184453
전체 등장 빈도에서 희귀 단어 등장 빈도 비율: 3.4019663890161915
→ 빈도수가 적은 단어를 제외한 단어사전의 크기는 8245이므로 8000으로 단어사전의 크기를 지정한다.
src_vocab = 8000
src_tokenizer = Tokenizer(num_words = src_vocab) # 단어 집합의 크기를 8,000으로 제한
src_tokenizer.fit_on_texts(encoder_input_train) # 단어 집합 재생성.
→ 학습데이터를 기반으로 만든 단어사전을 활용하여 텍스트 데이터를 정수 데이터로 변환한다.
# 텍스트 시퀀스를 정수 시퀀스로 변환
encoder_input_train = src_tokenizer.texts_to_sequences(encoder_input_train)
encoder_input_test = src_tokenizer.texts_to_sequences(encoder_input_test)
→ Summary부분에도 동일하게 적용한다.
tar_tokenizer = Tokenizer()
tar_tokenizer.fit_on_texts(decoder_input_train)
threshold = 6
total_cnt = len(tar_tokenizer.word_index) # 단어의 수
rare_cnt = 0 # 등장 빈도수가 threshold보다 작은 단어의 개수를 카운트
total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합
rare_freq = 0 # 등장 빈도수가 threshold보다 작은 단어의 등장 빈도수의 총 합
# 단어와 빈도수의 쌍(pair)을 key와 value로 받는다.
for key, value in tar_tokenizer.word_counts.items():
total_freq = total_freq + value
# 단어의 등장 빈도수가 threshold보다 작으면
if(value < threshold):
rare_cnt = rare_cnt + 1
rare_freq = rare_freq + value
print('단어 집합(vocabulary)의 크기 :',total_cnt)
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print('단어 집합에서 희귀 단어를 제외시킬 경우의 단어 집합의 크기 %s'%(total_cnt - rare_cnt))
print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100)
print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100)
# 출력결과
단어 집합(vocabulary)의 크기 : 10532
등장 빈도가 5번 이하인 희귀 단어의 수: 8141
단어 집합에서 희귀 단어를 제외시킬 경우의 단어 집합의 크기 2391
단어 집합에서 희귀 단어의 비율: 77.29775921002658
전체 등장 빈도에서 희귀 단어 등장 빈도 비율: 5.896799556127124
tar_vocab = 2000
tar_tokenizer = Tokenizer(num_words = tar_vocab)
tar_tokenizer.fit_on_texts(decoder_input_train)
tar_tokenizer.fit_on_texts(decoder_target_train)
# 텍스트 시퀀스를 정수 시퀀스로 변환
decoder_input_train = tar_tokenizer.texts_to_sequences(decoder_input_train)
decoder_target_train = tar_tokenizer.texts_to_sequences(decoder_target_train)
decoder_input_test = tar_tokenizer.texts_to_sequences(decoder_input_test)
decoder_target_test = tar_tokenizer.texts_to_sequences(decoder_target_test)
→ 빈도수가 낮은 단어를 삭제했으므로 이로인해 문장자체가 사라졌을 수 있다.
→ 이를 확인하여 배제한다.
drop_train = [index for index, sentence in enumerate(decoder_input_train) if len(sentence) == 1]
drop_test = [index for index, sentence in enumerate(decoder_input_test) if len(sentence) == 1]
print('삭제할 훈련 데이터의 개수 :',len(drop_train))
print('삭제할 테스트 데이터의 개수 :',len(drop_test))
encoder_input_train = np.delete(encoder_input_train, drop_train, axis=0)
decoder_input_train = np.delete(decoder_input_train, drop_train, axis=0)
decoder_target_train = np.delete(decoder_target_train, drop_train, axis=0)
encoder_input_test = np.delete(encoder_input_test, drop_test, axis=0)
decoder_input_test = np.delete(decoder_input_test, drop_test, axis=0)
decoder_target_test = np.delete(decoder_target_test, drop_test, axis=0)
print('훈련 데이터의 개수 :', len(encoder_input_train))
print('훈련 레이블의 개수 :',len(decoder_input_train))
print('테스트 데이터의 개수 :',len(encoder_input_test))
print('테스트 레이블의 개수 :',len(decoder_input_test))
# 출력결과
삭제할 훈련 데이터의 개수 : 1261
삭제할 테스트 데이터의 개수 : 328
훈련 데이터의 개수 : 51394
훈련 레이블의 개수 : 51394
테스트 데이터의 개수 : 12835
테스트 레이블의 개수 : 12835
패딩하기
→ 문장의 길이가 다르므로 위에서 지정했던 최대길이를 기준으로 패딩을 추가한다.
encoder_input_train = pad_sequences(encoder_input_train, maxlen = text_max_len, padding='post')
encoder_input_test = pad_sequences(encoder_input_test, maxlen = text_max_len, padding='post')
decoder_input_train = pad_sequences(decoder_input_train, maxlen = summary_max_len, padding='post')
decoder_target_train = pad_sequences(decoder_target_train, maxlen = summary_max_len, padding='post')
decoder_input_test = pad_sequences(decoder_input_test, maxlen = summary_max_len, padding='post')
decoder_target_test = pad_sequences(decoder_target_test, maxlen = summary_max_len, padding='post')
모델 설계
Encoder
from tensorflow.keras.layers import Input, LSTM, Embedding, Dense, Concatenate
from tensorflow.keras.models import Model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# 인코더 설계 시작
embedding_dim = 128
hidden_size = 256
# 인코더
encoder_inputs = Input(shape=(text_max_len,))
# 인코더의 임베딩 층
enc_emb = Embedding(src_vocab, embedding_dim)(encoder_inputs)
# 인코더의 LSTM 1
encoder_lstm1 = LSTM(hidden_size, return_sequences=True, return_state=True ,dropout = 0.4, recurrent_dropout = 0.4)
encoder_output1, state_h1, state_c1 = encoder_lstm1(enc_emb)
# 인코더의 LSTM 2
encoder_lstm2 = LSTM(hidden_size, return_sequences=True, return_state=True, dropout=0.4, recurrent_dropout=0.4)
encoder_output2, state_h2, state_c2 = encoder_lstm2(encoder_output1)
# 인코더의 LSTM 3
encoder_lstm3 = LSTM(hidden_size, return_state=True, return_sequences=True, dropout=0.4, recurrent_dropout=0.4)
encoder_outputs, **state_h, state_c**= encoder_lstm3(encoder_output2)
Decoder
# 디코더 설계
decoder_inputs = Input(shape=(None,))
# 디코더의 임베딩 층
dec_emb_layer = Embedding(tar_vocab, embedding_dim)
dec_emb = dec_emb_layer(decoder_inputs)
# 디코더의 LSTM
decoder_lstm = LSTM(hidden_size, return_sequences = True, return_state = True, dropout = 0.4, recurrent_dropout=0.2)
decoder_outputs, _, _ = decoder_lstm(dec_emb, initial_state = [**state_h, state_c**])
# 디코더의 출력층
decoder_softmax_layer = Dense(tar_vocab, activation = 'softmax')
decoder_softmax_outputs = decoder_softmax_layer(decoder_outputs)
# 모델 정의
model = Model([encoder_inputs, decoder_inputs], decoder_softmax_outputs)
model.summary()
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 50)] 0
__________________________________________________________________________________________________
embedding_2 (Embedding) (None, 50, 128) 1024000 input_3[0][0]
__________________________________________________________________________________________________
lstm_4 (LSTM) [(None, 50, 256), (N 394240 embedding_2[0][0]
__________________________________________________________________________________________________
input_4 (InputLayer) [(None, None)] 0
__________________________________________________________________________________________________
lstm_5 (LSTM) [(None, 50, 256), (N 525312 lstm_4[0][0]
__________________________________________________________________________________________________
embedding_3 (Embedding) (None, None, 128) 256000 input_4[0][0]
__________________________________________________________________________________________________
lstm_6 (LSTM) [(None, 50, 256), (N 525312 lstm_5[0][0]
__________________________________________________________________________________________________
lstm_7 (LSTM) [(None, None, 256), 394240 embedding_3[0][0]
lstm_6[0][1]
lstm_6[0][2]
__________________________________________________________________________________________________
dense_1 (Dense) (None, None, 2000) 514000 lstm_7[0][0]
==================================================================================================
Total params: 3,633,104
Trainable params: 3,633,104
Non-trainable params: 0
__________________________________________________________________________________________________
Attention
urllib.request.urlretrieve("<https://raw.githubusercontent.com/thushv89/attention_keras/master/src/layers/attention.py>", filename="attention.py")
from attention import AttentionLayer
`# 어텐션 층(어텐션 함수)`
`attn_layer = AttentionLayer(name='attention_layer')`
`# 인코더와 디코더의 모든 time step의 hidden state를 어텐션 층에 전달하고 결과를 리턴`
`attn_out, attn_states = attn_layer([encoder_outputs, decoder_outputs])`
``
`# 어텐션의 결과와 디코더의 hidden state들을 연결`
`decoder_concat_input = Concatenate(axis = -1, name='concat_layer')([decoder_outputs, attn_out])`
``
`# 디코더의 출력층`
`decoder_softmax_layer = Dense(tar_vocab, activation='softmax')`
`decoder_softmax_outputs = decoder_softmax_layer(decoder_concat_input)`
``
`# 모델 정의`
`model = Model([encoder_inputs, decoder_inputs], decoder_softmax_outputs)`
`model.summary()`
Model: "model_2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 50)] 0
__________________________________________________________________________________________________
embedding_2 (Embedding) (None, 50, 128) 1024000 input_3[0][0]
__________________________________________________________________________________________________
lstm_4 (LSTM) [(None, 50, 256), (N 394240 embedding_2[0][0]
__________________________________________________________________________________________________
input_4 (InputLayer) [(None, None)] 0
__________________________________________________________________________________________________
lstm_5 (LSTM) [(None, 50, 256), (N 525312 lstm_4[0][0]
__________________________________________________________________________________________________
embedding_3 (Embedding) (None, None, 128) 256000 input_4[0][0]
__________________________________________________________________________________________________
lstm_6 (LSTM) [(None, 50, 256), (N 525312 lstm_5[0][0]
__________________________________________________________________________________________________
lstm_7 (LSTM) [(None, None, 256), 394240 embedding_3[0][0]
lstm_6[0][1]
lstm_6[0][2]
__________________________________________________________________________________________________
attention_layer (AttentionLayer ((None, None, 256), 131328 lstm_6[0][0]
lstm_7[0][0]
__________________________________________________________________________________________________
concat_layer (Concatenate) (None, None, 512) 0 lstm_7[0][0]
attention_layer[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, None, 2000) 1026000 concat_layer[0][0]
==================================================================================================
Total params: 4,276,432
Trainable params: 4,276,432
Non-trainable params: 0
__________________________________________________________________________________________________
→ Encoder의 Hidden state와 Decoder의 Hidden state들을 어텐션 함수의 입력으로 사용하고, 어텐션 함수가 리턴한 값을 예측 시에 Decoder의 Hidden state와 함께 활용한다.
모델 훈련
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy')
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience = 2)
history = model.fit(x = [encoder_input_train, decoder_input_train], y = decoder_target_train, \\
validation_data = ([encoder_input_test, decoder_input_test], decoder_target_test),
batch_size = 256, callbacks=[es], epochs = 50)
`Epoch 1/50
201/201 [==============================] - 70s 349ms/step - loss: 2.7020 - val_loss: 2.3948
Epoch 2/50
201/201 [==============================] - 73s 365ms/step - loss: 2.3792 - val_loss: 2.2564
Epoch 3/50
201/201 [==============================] - 71s 351ms/step - loss: 2.2437 - val_loss: 2.1450
Epoch 4/50
201/201 [==============================] - 70s 347ms/step - loss: 2.1271 - val_loss: 2.0614
Epoch 5/50
201/201 [==============================] - 69s 346ms/step - loss: 2.0412 - val_loss: 2.0038
Epoch 6/50
201/201 [==============================] - 69s 345ms/step - loss: 1.9742 - val_loss: 1.9620
Epoch 7/50
201/201 [==============================] - 69s 344ms/step - loss: 1.9215 - val_loss: 1.9230
Epoch 8/50
201/201 [==============================] - 69s 342ms/step - loss: 1.8748 - val_loss: 1.9038
Epoch 9/50
201/201 [==============================] - 69s 343ms/step - loss: 1.8340 - val_loss: 1.8829
Epoch 10/50
201/201 [==============================] - 69s 342ms/step - loss: 1.7966 - val_loss: 1.8737
Epoch 11/50
201/201 [==============================] - 69s 343ms/step - loss: 1.7627 - val_loss: 1.8649
Epoch 12/50
201/201 [==============================] - 69s 343ms/step - loss: 1.7305 - val_loss: 1.8507
Epoch 13/50
201/201 [==============================] - 68s 340ms/step - loss: 1.7012 - val_loss: 1.8431
Epoch 14/50
201/201 [==============================] - 68s 338ms/step - loss: 1.6732 - val_loss: 1.8380
Epoch 15/50
201/201 [==============================] - 70s 347ms/step - loss: 1.6466 - val_loss: 1.8340
Epoch 16/50
201/201 [==============================] - 69s 345ms/step - loss: 1.6213 - val_loss: 1.8327
Epoch 17/50
201/201 [==============================] - 68s 340ms/step - loss: 1.5969 - val_loss: 1.8332
Epoch 18/50
201/201 [==============================] - 66s 330ms/step - loss: 1.5740 - val_loss: 1.8306
Epoch 19/50
201/201 [==============================] - 67s 333ms/step - loss: 1.5515 - val_loss: 1.8353
Epoch 20/50
201/201 [==============================] - 69s 342ms/step - loss: 1.5309 - val_loss: 1.8327
Epoch 00020: early stopping`
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()

인퍼런스 모델 구현
→ 테스트 시에 필요한 텍스트 데이터를 준비한다.
src_index_to_word = src_tokenizer.index_word # 원문 단어 집합에서 정수 -> 단어를 얻음
tar_word_to_index = tar_tokenizer.word_index # 요약 단어 집합에서 단어 -> 정수를 얻음
tar_index_to_word = tar_tokenizer.index_word # 요약 단어 집합에서 정수 -> 단어를 얻음
→ 정답 문장이 없는 테스트의 경우 만들어야 할 문장의 길이만큼 디코더가 반복구조로 동작한다.
# 인코더 설계
encoder_model = Model(inputs=encoder_inputs, outputs=[encoder_outputs, state_h, state_c])
# 이전 시점의 상태들을 저장하는 텐서
decoder_state_input_h = Input(shape=(hidden_size,))
decoder_state_input_c = Input(shape=(hidden_size,))
dec_emb2 = dec_emb_layer(decoder_inputs)
# 문장의 다음 단어를 예측하기 위해서 초기 상태(initial_state)를 이전 시점의 상태로 사용. 이는 뒤의 함수 decode_sequence()에 구현
# 훈련 과정에서와 달리 LSTM의 리턴하는 은닉 상태와 셀 상태인 state_h와 state_c를 버리지 않음.
decoder_outputs2, state_h2, state_c2 = decoder_lstm(dec_emb2, initial_state=[decoder_state_input_h, decoder_state_input_c])
# 어텐션 함수
decoder_hidden_state_input = Input(shape=(text_max_len, hidden_size))
attn_out_inf, attn_states_inf = attn_layer([decoder_hidden_state_input, decoder_outputs2])
decoder_inf_concat = Concatenate(axis=-1, name='concat')([decoder_outputs2, attn_out_inf])
# 디코더의 출력층
decoder_outputs2 = decoder_softmax_layer(decoder_inf_concat)
# 최종 디코더 모델
decoder_model = Model(
[decoder_inputs] + [decoder_hidden_state_input,decoder_state_input_h, decoder_state_input_c],
[decoder_outputs2] + [state_h2, state_c2])
→ 모델을 활용하여 문장을 완성하는 함수를 만든다.
def decode_sequence(input_seq):
# 입력으로부터 인코더의 상태를 얻음
e_out, e_h, e_c = encoder_model.predict(input_seq)
# <SOS>에 해당하는 토큰 생성
target_seq = np.zeros((1,1))
target_seq[0, 0] = tar_word_to_index['sostoken']
stop_condition = False
decoded_sentence = ''
while not stop_condition: # stop_condition이 True가 될 때까지 루프 반복
output_tokens, h, c = decoder_model.predict([target_seq] + [e_out, e_h, e_c])
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_token = tar_index_to_word[sampled_token_index]
if(sampled_token!='eostoken'):
decoded_sentence += ' '+sampled_token
# <eos>에 도달하거나 최대 길이를 넘으면 중단.
if (sampled_token == 'eostoken' or len(decoded_sentence.split()) >= (summary_max_len-1)):
stop_condition = True
# 길이가 1인 타겟 시퀀스를 업데이트
target_seq = np.zeros((1,1))
target_seq[0, 0] = sampled_token_index
# 상태를 업데이트 합니다.
e_h, e_c = h, c
return decoded_sentence
모델 테스트
→ 인퍼런스 모델을 구현할 때 만들었던 정수→단어 사전을 활용하여 정수데이터를 문장으로 바꾸어 확인한다.
# 원문의 정수 시퀀스를 텍스트 시퀀스로 변환
def seq2text(input_seq):
temp=''
for i in input_seq:
if(i!=0):
temp = temp + src_index_to_word[i]+' '
return temp
# 요약문의 정수 시퀀스를 텍스트 시퀀스로 변환
def seq2summary(input_seq):
temp=''
for i in input_seq:
if((i!=0 and i!=tar_word_to_index['sostoken']) and i!=tar_word_to_index['eostoken']):
temp = temp + tar_index_to_word[i] + ' '
return temp
for i in range(50, 100):
print("원문 :", seq2text(encoder_input_test[i]))
print("실제 요약 :", seq2summary(decoder_input_test[i]))
print("예측 요약 :", decode_sequence(encoder_input_test[i].reshape(1, text_max_len)))
print("\\n")
# 출력결과
원문 : bars taste great good loaded sugars preservatives like ones grocery shelves instead loaded healthy stuff appreciate year old yummy factor package great heat microwave seconds make even better crumble yogurt eat run looking forward trying flavors fyi smaller square bars also quite good get top rating
실제 요약 : great combo of yummy healthy
예측 요약 : great for protein shakes
원문 : pet sitting recently dog sitting treat pouch loved tried dogs dogs quite well whenever saw reach goodies son call doggie crack good work training else ask dog treat
실제 요약 : does not get much better
예측 요약 : my dog loves these
원문 : recently ordered organic apple candy candies light almost refreshing apple flavor favorite far highly recommend product
실제 요약 : these are my favorite
예측 요약 : delicious
원문 : product arrived less time expected neat sack code showing te exact lot land particular bag beans cooked large batch right away delicous perfect love usa grown product found new source dry staples back order
실제 요약 : wonderful product cannot wait to get more
예측 요약 : great service
원문 : great flavor subtle like chocolate one really hit mark one
실제 요약 : delicious
예측 요약 : great taste
원문 : fabulous gift ordered kept one try awesome presentation great chocolates delicate creamy crunchy tasty easy eat heavy mass produced line real winner better price range love different flavors buy great hostess gift
실제 요약 : so yummy wonderful inexpensive gift item
예측 요약 : great gift
원문 : girlfriend rarely caffeine heart cannot help always little cup make pot weavers organic blend french roast worth try must say absolute favorite organic blend taste others
실제 요약 : should not be
예측 요약 : great coffee
원문 : tastes great found product walmart price really update double checked price walmart product amount costs compared
실제 요약 : bad price on miso
예측 요약 : great price
원문 : visiting san diego area summer got chance try different sauces indian cook god taste good best indian gourmet sauces ever tasted us believe tried lot products wish start selling midwest
실제 요약 : best gourmet indian
예측 요약 : great sauce
원문 : brewed coffee almost non existent family would almost always buy instant coffee brewed coffee never tasted quite right coffee like one day brother brought home free samples understood people loves brewed coffee flavor taste simply blew away
실제 요약 : this is what me
예측 요약 : great coffee
원문 : little bit leery trying cashews pepper pleasantly suprised black pepper complements cashews well kicks taste notch emerald canister products quality excellent canister fashioned fit car cup holder top handy measuring cup serving really enjoyed
실제 요약 : cashews with kick
예측 요약 : great
원문 : opened peanuts expecting set taste buds quite dissapointed definitely spicy lacked heat name implies totally love hot sauce name guess expected nuts degree hot quite good would enjoyable feel hot none habanero fire expected
실제 요약 : not all that hot
예측 요약 : not hot hot
원문 : know read description closely sugar drink people rating high tea use whey instead sugar way less useless calories oh give two cans without feeling guilty
실제 요약 : sugar sugar sugar
예측 요약 : coconut oil
원문 : thing liked came small packages delivered quickly fresh
실제 요약 : haribo gummi candy
예측 요약 : great
원문 : hoping pears would mask spinach peas flavor daughter care
실제 요약 : tastes more like than
예측 요약 : not my cat likes it
원문 : personally enjoyed almonds cocoa roast almonds better admit particular choice okay especially way pepper tends bring distinctive flavor two things consider try remember keep handy might want beverage wash maybe personal first choice decent
실제 요약 : emerald sea salt pepper cashew ounces
예측 요약 : great taste
원문 : wilton products excellent taste artificial vanilla strong however recipes use full amount asked reduce purchase several time bakery mexican real vanilla used
실제 요약 : good taste for an artificial vanilla
예측 요약 : good stuff
원문 : love stuff treat put flax oil brewers yeast much comfort food
실제 요약 : yum
예측 요약 : great product
원문 : gluten free diet many desserts alternative wafers delicious texture taste wonderful better many famous brand wafers negative thing tend melt fast always store fridge
실제 요약 : wonderful taste
예측 요약 : great gluten free
원문 : enjoyed carbonation hint blackberry liked fact calories artificial sweeteners
실제 요약 : refreshing with zero artificial
예측 요약 : good but not great
원문 : wow best tea ever pleasure drinking sorry
실제 요약 : love this tea
예측 요약 : best tea ever
원문 : kids love paid bags amazon came back costco paid bags whole lot cheaper costco
실제 요약 : much cheaper at costco store
예측 요약 : great price
원문 : think title says ingredients exactly would choose texture bit odd taste really good nutrition info fits within diet
실제 요약 : really good and not terrible for you
예측 요약 : not bad
원문 : far best gf cracker market hold nicely toppings added year old son really likes fussy eater able find decent gf bread sandwiches crackers couple thick pieces gf head ham happy camper
실제 요약 : delicious
예측 요약 : great pasta
원문 : reason give san francisco bay fog chaser star open sealed bag coffee stay fresh long enjoyed coffee great aroma love packaging reduced plastic compared original kcups main thing loved price figure way retain freshness gold san francisco bay coffee one cup keurig cup brewers fog chaser count
실제 요약 : great deal
예측 요약 : great coffee
원문 : love hot teas never tried chai someone suggested one perfect time bit sugar little milk added wonderful flavor overpoweringly spicy right also fine without milk milk smooth spices bit buy couple six pack boxes time pretty sure couple cups every night addiction
실제 요약 : am addicted
예측 요약 : great tea
원문 : love stuff make oz setting cuisinart cup machine add steamed milk makes wonderful hot chocolate latte chocolate good well although like add least splash milk thicken body little
실제 요약 : expensive but tastes great
예측 요약 : great taste
원문 : nothing better rishi teas tea drinker years tried rishi earl grey treat pound regularly
실제 요약 : top of the
예측 요약 : great tea
원문 : food loved easy take us go road trips
실제 요약 : great food
예측 요약 : great food
원문 : huge dried fruit fan dried fruit snacks marketplace soft crunchy taste awesome cannot beat nutritional benefits well like many favorites subscribe save save little extra month ever run
실제 요약 : love these crunchy dried fruit snacks
예측 요약 : delicious
원문 : one would resort canned coffee real coffee available basis review drink still prefer real thing canned coffee really bad nice strong less sugar coffee drinks would actually prefer even less sweetener find bit unusual case closest ready made beverage found tastes like real espresso definitely appreciate convenience
실제 요약 : to the real thing
예측 요약 : just ok
원문 : purchased item bake hesitant order due negative reviews dented cans packaging went ahead ordered received free shipping whole case delivered dent free entire case pumpkin bubble wrapped enclosed box taste product great little less dense usual libby baked past definitely purchase
실제 요약 : packaged extremely well
예측 요약 : great product
원문 : tried cookies glass milk lived bought small grocery washington dc business saved wrapper googled bought amazon quick service product fresh happy caution addicting let one two time whole box
실제 요약 : yummy
예측 요약 : great cookie
원문 : ordered amazon longer seem find local stores part daily lunch found anything like well price amazon fair ship arrive quickly another reviewer mentioned rounds inside boxes broken happened well point ruins product thrilled found outlet buying bagel snacks
실제 요약 : old original snacks
예측 요약 : great product
원문 : oregon chai tea brews fast tastes better commercial chai tea oh much better starbuck much economical truly yummy treat
실제 요약 : heavenly tea
예측 요약 : chai chai tea
원문 : bought freeze dried liver half container filled powder instead pieces chunks feel company hence get paid
실제 요약 : not
예측 요약 : not as good as the
원문 : overwhelmed product okay certain would make extra effort look product grocery store
실제 요약 : meh
예측 요약 : no
원문 : spearmint water amazing drink cold workout refreshing sugar calories really pure simple mint water
실제 요약 : so minty fresh
예측 요약 : the best
원문 : oh man adore flavor bar yes boy come closet eaters one concern august listing specify many bars box paying cents per bar better trader bb bulk think bulk places might beat caveat flavor delicious
실제 요약 : delicious new flavor two
예측 요약 : delicious
원문 : german haribo best one good german ones ever germany visit plus supermarket purchase cents germany go haribo plant started otherwise amazon best price choose free shipping
실제 요약 : there
예측 요약 : best candy ever
원문 : best jamaican curry powder taste like get non hot version control spiciness addition fresh peppers outstanding curry powder love
실제 요약 : real taste of jamaica
예측 요약 : great sauce
원문 : eat almost every yet tire eat dry eat milk beef offered bulk sizes type stores never coupons start buying bulk amazon little cheaper way plain simple damn good cereal
실제 요약 : the best cereal ever hands down
예측 요약 : great for
원문 : since diagnosed celiac disease three years ago pretty much given bread edible thrilled product available best gluten free bread ever eaten simple make bread machine gluten free setting pound breadmaker stainless steel
실제 요약 : gluten free bread
예측 요약 : best gluten free bread mix
원문 : nice medium coffee strong weak good flavor bitter typical go donut blend tried one cheaper think go back
실제 요약 : nice medium roast
예측 요약 : good coffee
원문 : good product almost popcorn pops fluffy snow white air popper great snack calories taste great
실제 요약 : white popcorn
예측 요약 : great popcorn
원문 : like licorice enjoy theses perfect tiny powerful typically hard candy fan
실제 요약 : must like licorice
예측 요약 : licorice
원문 : eating lot dried mango lately tried several brands one far favorite feel compelled write review pro taste tastes like mango maintaining hint moisture seldom found less desirable bites happens brands pretty often cons small amount bag neutral agree another poster bites small pro con
실제 요약 : favorite dried
예측 요약 : good taste but not that is sugar
원문 : wrote oskri asking soy organic least non gmo saying mini coconut milk chocolate bars certified organic even sent organic prove enjoy knowing organic
실제 요약 : these bars are organic even the soy
예측 요약 : contains
원문 : favorite brand coconut water usually prefer plain natural variety guava flavor definitely best flavored coconut waters offer like plain coconut water great product try especially like guava husband like plain coconut water like flavored varieties
실제 요약 : delicious
예측 요약 : great taste
원문 : dry product extremely fine almost powdery cooked product mushy even taste like grits like coarse stone ground grits de regular white grits grocery store product donate three unopened boxes local food bank
실제 요약 : not for true grits lovers
예측 요약 : nasty
'[NLP 공부정리]' 카테고리의 다른 글
| [3주차] 다음에 볼 영화 예측하기 (0) | 2021.06.21 |
|---|---|
| [2주차] 당신이 좋아할 만한 다른 아티스트 찾기 (0) | 2021.05.02 |
| [1주차]영화리뷰 텍스트 감성분석하기 (0) | 2021.04.24 |